ADF zonder een SSIS-IR, kan dat? Jazeker! Natuurlijk nog wel sterk leunend op database activiteiten m.b.v. stored procedures.
Laten we beginnen met de ‘scope’ om een situatie te schetsen. Voor deze oplossing heb ik een viertal bestanden klaargezet op een Azure File Share en deze moeten natuurlijk worden ingelezen en ‘verwerkt’ worden binnen een historische database (ook wel HSTG):

Om deze bestanden te kunnen verwerken, heb ik de volgende pipeline gemaakt binnen ADF:
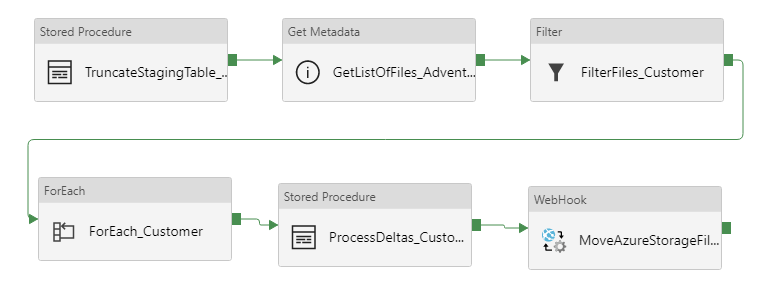
De betreffende Customer-staging-tabel wordt als eerste geleegd, ‘start fresh’. Vervolgens wordt een lijst samengesteld met alle aanwezige CSV-bestanden binnen de Azure File Share, daarna worden deze gefilterd op basis van de prefix ‘Customer*‘. Voor ieder bestand worden vervolgens de volgende taken uitgevoerd:

De CSV-bestanden worden stuk-voor-stuk ingelezen en de data wordt gekopiëerd naar de Customer-staging-tabel. Vervolgens ben ik wel geïnteresseerd in de [FILENAME] en [FILEDATE], deze voeg ik toe aan het record d.m.v. een stored procedure. Laatste stap is om logging weg te schrijven per verwerkt bestand:

Terug naar de pipeline voor de laatste twee stappen (zodra alle bestanden zijn verwerkt):
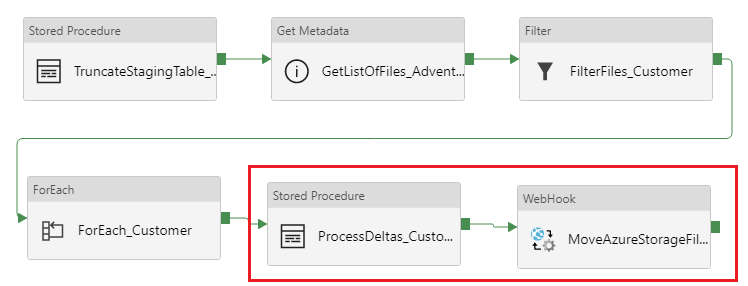
Ik roep vervolgens een stored procedure aan om de nieuwe staging-data te verwerken en op te slaan binnen de historische-tabel (delta’s detecteren). Dit duurt al met al zo’n 10 seconden gemiddeld per bestand met de database scale op ‘Basic’:

Historisch gezien ziet het er dan als volgt uit:

De laatste stap is het verplaatsen van de CSV-bestanden naar een archiefmap binnen de Azure File Share. Dit doe ik middels een PowerShell-script (binnen een Automation Account), dat ik dan aanroep middels een WebHook-activiteit.
De totale oplossing ziet er als volgt uit binnen de database (nu enkel met een Customer-entiteit):
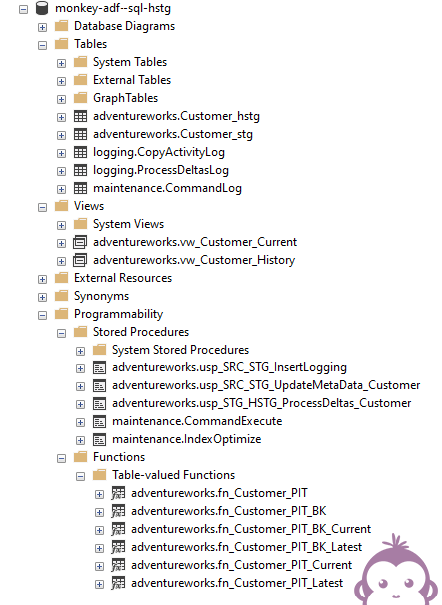
De Point-In-Time (PIT) functies bieden historische inzichten m.b.t. de data. Niet alleen een ‘current’-view, maar écht terugkijken in de tijd. Meer lees je er hier over.
Met betrekking tot de run-time kosten van deze oplossing , dit valt het reuze mee moet ik zeggen. Als test heb ik de bovenstaande Copy Data activiteit een aantal keren uitgevoerd:

Als ik kijk naar de Azure-kosten, dan kom ik hiervoor ongeveer uit op zo’n € 4,20 voor 240 executions. Ter vergelijking zou je dus zo’n 200 aparte bestanden/objecten kunnen verwerken met verschillende groottes voor zo’n € 5,- per dag schat ik.
Conclusie
Binnen ADF delta’s verwerken zonder gebruik te maken van SSIS-packages is zeker mogelijk. Al zijn er nog veel ontwikkelingen gaande achter de schermen bij Microsoft en wel het volgende:
Wrangling Data Flow
ADF is nog vrij nieuw (zo’n 2 a 3 jaren oud denk ik?) en je merkt dat Microsoft aan de ‘achterkant‘ nog flink aan het ontwikkelen is. Gemakkelijk je M-code uit Power BI gebruiken binnen ADF (middels copy/paste)? Dan krijg je een soort Self-Service-ExtractLoad (EL) vs Enterprise-ExtractLoad. lees: Wrangling Data Flows
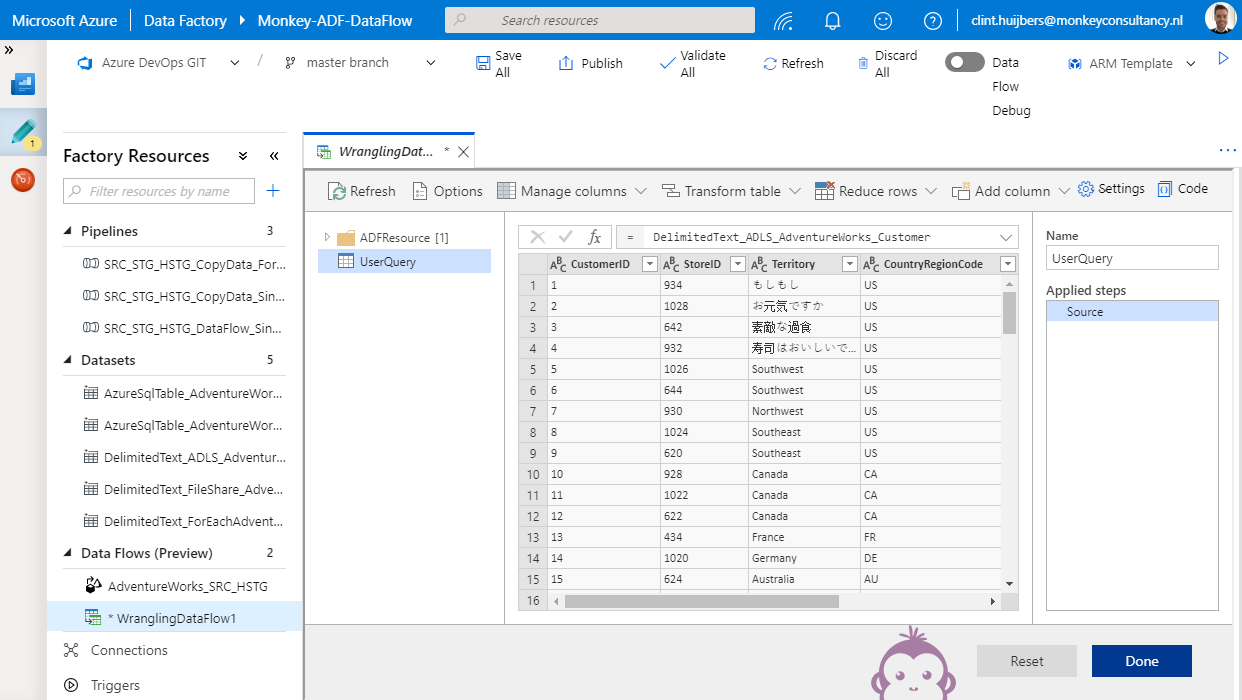
Data Flow
ADF Data Flow is héél nieuw en bevat op dit moment de ‘basis’-componenten voor het verwerken van data. Natuurlijk nog lang niet dezelfde functionaliteiten als SSIS (bijvoorbeeld foutafhandeling binnen de data flow) en er vinden erg veel updates en vernieuwingen plaats. Het uitvoeren van een Data Flow duurt (bij mij) erg lang (!) voor het kopiëren van data van één enkel bestand…
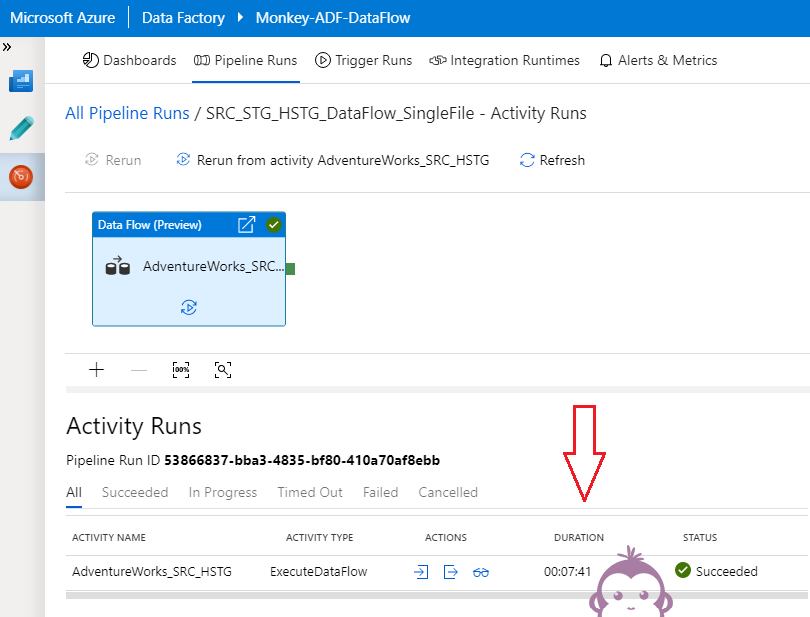
Volgens mij zit 99% van de tijd in het opstarten van een DataBricks-cluster. Helaas kun je niet precies zien waar de tijd in gaat zitten, maar wel het volgende binnen Data Flow:
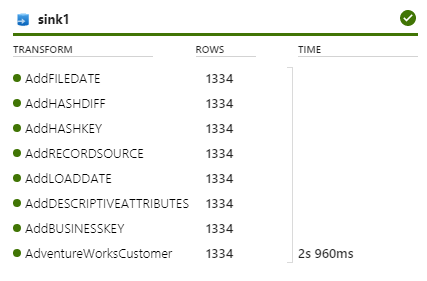
Nog niet ideaal om vol op te duiken en dit alles in een framework te gieten 🙂 Al heb ik wel het idee dat het uitvoeren van Data Flows een stuk duurder is dan het uitvoeren van ‘simpele’ Copy Activity pipelines (zoals het voorbeeld bovenaan). Microsoft gaat over op een ‘betalen-per-activiteit’ business model en je raad het al, dit zal voor grote aantallen zeker niet voordeliger zijn. Hoe dan ook is het onvermijdelijk en zullen we de komende jaren allemaal afscheid nemen van SSIS(-IR).
Nieuwsgierig naar de mogelijkheden van Azure en DevOps binnen uw organisatie?
Neem dan contact met ons op: clint.huijbers@monkeyconsultancy.nl
